May 2026
LLM Cost-Optimisation Benchmark v1
How four production frontier models perform under batch, compression, and output-cap levers — an empirical benchmark of 1,280 scored responses across four task categories, May 2026.
TL;DR
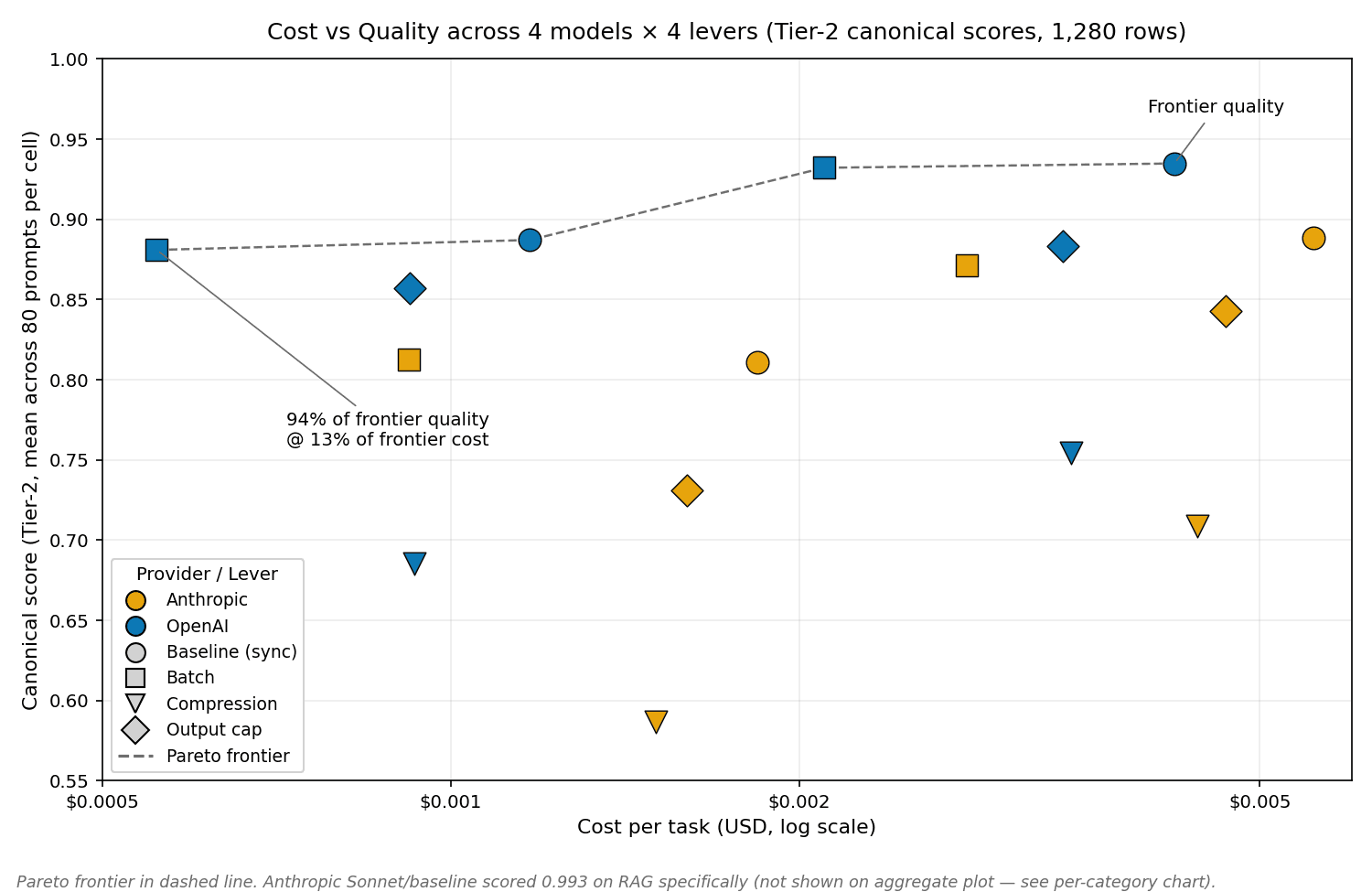
If you are running LLM workloads in production and want to apply cost optimisations without paying for them in quality, the answer for most task shapes is gpt-5.4-mini + batch. That cell delivers canonical quality 0.881 at $0.000557 per task — 94.2% of the frontier quality available across the 16 (model, lever) combinations we tested, at 13.2% of the frontier cost. The frontier itself (gpt-5.4 + baseline at canon 0.935, $0.004220 per task) costs 7.6× more for the remaining 5.4 canonical points.
Across all four models and four task categories, six findings are robust enough to act on:
- Batch is universally near-free. ~50% cost cut for ≤2% canonical loss across every model and every task category. On GPT-5.4 specifically, batch produces a bit-for-bit identical Tier-1 pass set vs sync at temperature=0 (54/54 prompts).
- Compression damages quality universally (−18 to −22 canonical points aggregate), catastrophic on RAG (−45 points, Tier-1 pass rate collapses 80% → 4%).
- Output cap is reasoning-specific damage. Fine on short-answer tasks (≤ −0.07 canonical). On multi-step reasoning, it costs −0.13 canonical because it truncates the answer.
- Provider dominance is task-shaped, not universal. OpenAI Pareto-dominates the aggregate frontier (4/4 cells) and wins reasoning + summarisation outright. Anthropic Sonnet wins RAG with canon 0.993 (highest cell anywhere), beating the best non-Sonnet cell by 0.008.
- Anthropic models degrade more under optimisation pressure. On reasoning, the Sonnet-vs-GPT-5.4 gap widens from 0.027 at baseline to 0.093 under compression. If you are running Anthropic, avoid compression specifically.
- The cost-quality sweet spot depends on the task. Three categories tolerate 9–14× cost spread inside the near-best band; summarisation has only 4 near-best cells in a 2.2× band, its cheapest 30× more expensive than any other category's.
Why this benchmark exists
Production engineering teams running LLM workloads face a question every public benchmark sidesteps: which cost optimisations actually preserve quality on real workloads, and which ones quietly destroy it? Capability benchmarks (MMLU, GPQA, AIME) tell you which model is smartest at the frontier. They do not tell you whether enabling the batch API on your customer-support pipeline will save you 50% of cost at no quality loss — or whether enabling LLM-Lingua-style prompt compression on a RAG workload will silently halve your output quality.
The gap matters because the cost-quality decisions production teams actually make are about operational levers, not raw model selection. A team that has already chosen a model is now choosing between sync and batch, between full context and compressed context, between unbounded output and a max-tokens cap. These levers each carry different cost savings and different — often hidden — quality costs that depend on the task shape.
This v1 measures four frontier models (claude-haiku-4-5, claude-sonnet-4-6, gpt-5.4, gpt-5.4-mini) under four levers (baseline sync, batch, prompt compression, output cap) across four Tier-2-scored task categories (customer support, RAG QA, reasoning, summarisation), with 20 prompts per category — 80 prompts × 4 models × 4 levers = 1,280 scored responses. Every response was scored on a two-tier rubric (deterministic Tier-1, dual-judge Tier-2 with hybrid human arbitration on disagreements).
Methodology
Task taxonomy
The benchmark uses 102 prompts across five task categories chosen to cover the four production workload shapes that drive most enterprise inference spend, plus one Tier-1-only category for format-rigour testing:
- Customer support (20 prompts): inbox triage with structured JSON output — classify intent, draft a reply. Tests both content accuracy and output-format discipline.
- RAG QA (20 prompts): retrieval-grounded short-answer questions with supporting-citation requirements. Tests grounding fidelity and citation correctness.
- Reasoning (20 prompts): multi-step quantitative reasoning — proration calculations, conditional logic chains. Tests chained intermediate steps and final-answer correctness.
- Summarisation (20 prompts): long-document compression to executive summaries. Free-text output, no deterministic content check applies.
- Extraction (22 prompts, Tier-1-only): structured-field extraction from unstructured text. Excluded from Tier-2 judge scoring because the correct answer is exactly verifiable; included only in Tier-1 deterministic pass-rate analysis.
Models
Four production-tier frontier models, two per provider, chosen to give a flagship vs cost-tier comparison within each family: claude-sonnet-4-6 and claude-haiku-4-5 (Anthropic); gpt-5.4-2026-03-05 and gpt-5.4-mini-2026-03-17 (OpenAI). Full model IDs appear in CSVs and methodology; friendly names (sonnet, haiku, gpt-5.4, gpt-5.4-mini) appear throughout the writeup.
Levers
Four operational levers, each tested on the same 80 prompts × 4 models = 320 cells:
- Baseline (sync): standard synchronous API call. Reference cost and reference quality.
- Batch: provider batch API, ~24-hour turnaround. Costs 50% of sync at both providers.
- Compression: runtime prompt compression via LLM-Lingua at the lever boundary (not preprocessing). Targets 30–50% input-token reduction.
- Output cap: explicit max-tokens cap on the response, chosen per-task-category to reflect “what a sensible engineer would set”. Tests the trade-off between output budget and quality.
Two-tier scoring
Every response is scored on two independent tiers, so cost and quality can be evaluated jointly without a single metric collapsing both signals.
Tier-1 (deterministic): automated checks per task category — JSON validity, schema conformance, content checks against the expected answer. Produces a status enum (pass, fail_format, fail_schema, fail_content, truncated, compression_unavailable, not_applicable, error). Tier-1 pass rate gives the “is the output structurally usable” signal.
Tier-2 (judge-based): LLM judge panel scores each response on a category-specific rubric (0.0–1.0). The v1 panel is a two-judge cross-provider design: claude-opus-4-6 (Judge A) + gpt-5.5 (Judge B). Each judge scores independently against a pre-written rubric.
Judge panel and panel revision
The original v1 panel was Opus 4.6 + Mistral large 2512. After Day 10 produced 1,280 Tier-2 scores, an audit of judge behaviour surfaced three specific Mistral failure modes: non-determinism at temperature=0 (score drift across re-fires), score-reasoning desync, and — most critically — hallucinated completeness on truncated responses.
The canonical example: rea-015 / gpt-5.4 / output_cap. Mistral claimed “the response correctly arrives at the final answer” and assigned a high score on a reasoning prompt where the response had been truncated mid-computation by the output_cap lever. Mistral was scoring the answer it expected to see, not the response actually produced.
Three candidate replacements were evaluated against a 12-prompt targeted validation set: GPT-5.5 (passed 4/4 truncated-output catches, 0 hallucinations — adopted), Gemini 2.5 Pro (1/6 truncated-output hallucinations — rejected), Gemini 3.1 Pro Preview (rejected on operational grounds: ~14 minutes/call).
The panel revision cut disagreement count from 167 to 80 (13.0% → 6.2%, −52%) and eliminated a Mistral-driven cross-provider calibration offset.
Hybrid arbitration
Of the 80 panel disagreements (cases where |judge_a − judge_b| ≥ 0.3), 16 were arbitrated by a human operator. The remaining 64 (|Δ| ≤ 0.3) were resolved by median-canonical-auto — taking the midpoint between the two judges. Human-arbitrated cases concentrate on prompts where the judges disagreed substantively (one judge thought the answer was right, the other thought it was wrong); auto-median cases are smaller-magnitude calibration noise.
Findings
Finding 1 — Batch is operationally equivalent to sync (and 50% cheaper)
The empirically strongest version of this finding: on gpt-5.4 specifically, the batch endpoint produces a bit-for-bit identical Tier-1 pass set versus sync at temperature=0 — 54/54 pass intersection on 80 prompts, zero per-prompt divergence. The OpenAI batch endpoint is deterministic-equivalent to sync for this model.
Across the broader panel, the cost saving holds at provider-documented rates (0.476–0.501 cost ratios across all four models), and the quality cost is essentially zero: aggregate Δcanonical_score ranges from −0.017 (sonnet) to +0.001 (haiku); per-category Δcanon ranges from 0.000 to −0.015 (reasoning).
The practical implication is unambiguous: if your workload tolerates batch latency, switch. The 50% cost saving comes with no meaningful quality cost on any of the four task shapes we tested. The only reason not to enable batch is latency-sensitivity; the cost-quality decision itself is over.
Finding 2 — Compression is universally dominated, catastrophic on RAG
Prompt compression cuts cost by only 18–21% while reducing canonical_score by 18–22 points on aggregate ( Δcanon −0.180 to −0.224 across the four models).
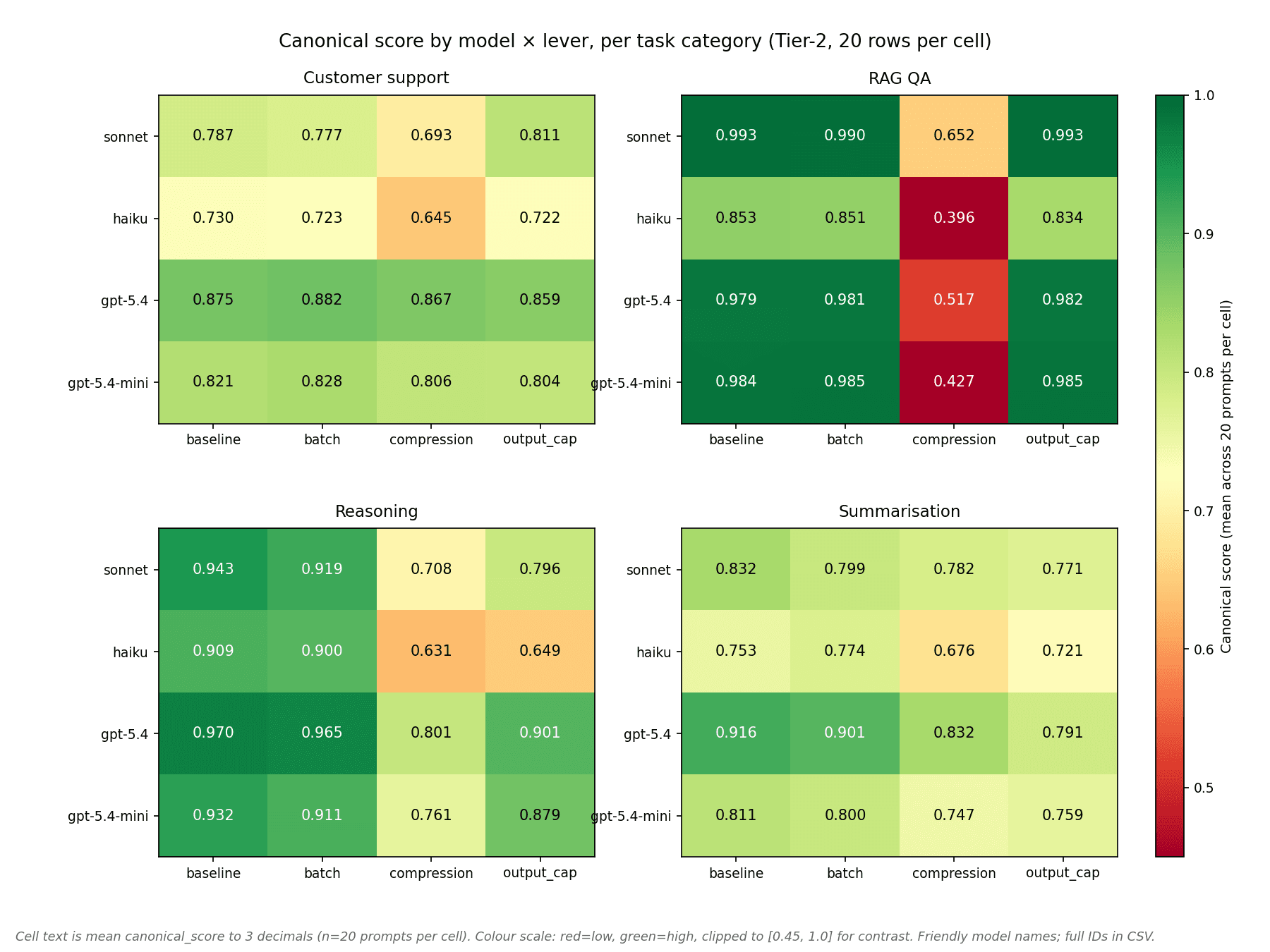
The category-level damage is wildly uneven. Customer support loses 5 canonical points to compression; summarisation 7; reasoning 21. Retrieval-grounded QA loses 45 canonical points — and that aggregate number understates the failure mode. The Tier-1 applicable pass rate on compressed RAG goes from 80.0% (baseline) to 3.8% (compression). Roughly 4 of every 100 compressed RAG outputs pass deterministic format/content checks.
No model and no task category recovers compression's quality cost. On the cost-quality frontier, the lever is dominated everywhere — for every (model, compression) cell, there is at least one (model, lever) cell with both higher canonical_score and lower cost.
Finding 3 — Output cap damage is reasoning-specific
The output-length cap is fine for short-answer tasks (Δcanon −0.004 on customer_support, −0.003 on rag_qa, −0.067 on summarisation) but costly for multi-step reasoning (Δcanon −0.132). Capping output cuts the reasoning chain before the answer arrives.
The asymmetry is sharp: output_cap costs roughly 4× more quality on reasoning than on the next-worst category (summarisation), and roughly 33× more than on customer_support. Use output_cap freely for classification, extraction, or short replies. Avoid it on tasks that require chained intermediate steps.
Finding 4 — Provider dominance is task-shaped, not universal
OpenAI models Pareto-dominate the aggregate cost-quality frontier (all four Pareto-optimal cells are gpt-5.4 or gpt-5.4-mini).
But the per-category Pareto frontiers tell a different story. On RAG QA the highest-canon cell in the entire 16-cell aggregate matrix is sonnet baseline at 0.993 — beating the best non-Sonnet RAG cell (gpt-5.4-mini batch at 0.985) by 0.008 canonical points.
The honest framing: OpenAI wins three of four categories outright; Anthropic Sonnet wins RAG. A team running mixed workloads should not pick a single provider on this benchmark alone; a team running mostly RAG should look at Sonnet seriously.
Finding 5 — Anthropic models degrade more under optimisation pressure
At baseline, the canonical-score gap between Sonnet and GPT-5.4 on reasoning is small: 0.943 vs 0.970, a 0.027-point gap. Under compression the gap widens to 0.708 vs 0.801 (0.093 points), and under output_cap to 0.796 vs 0.901 (0.105 points).
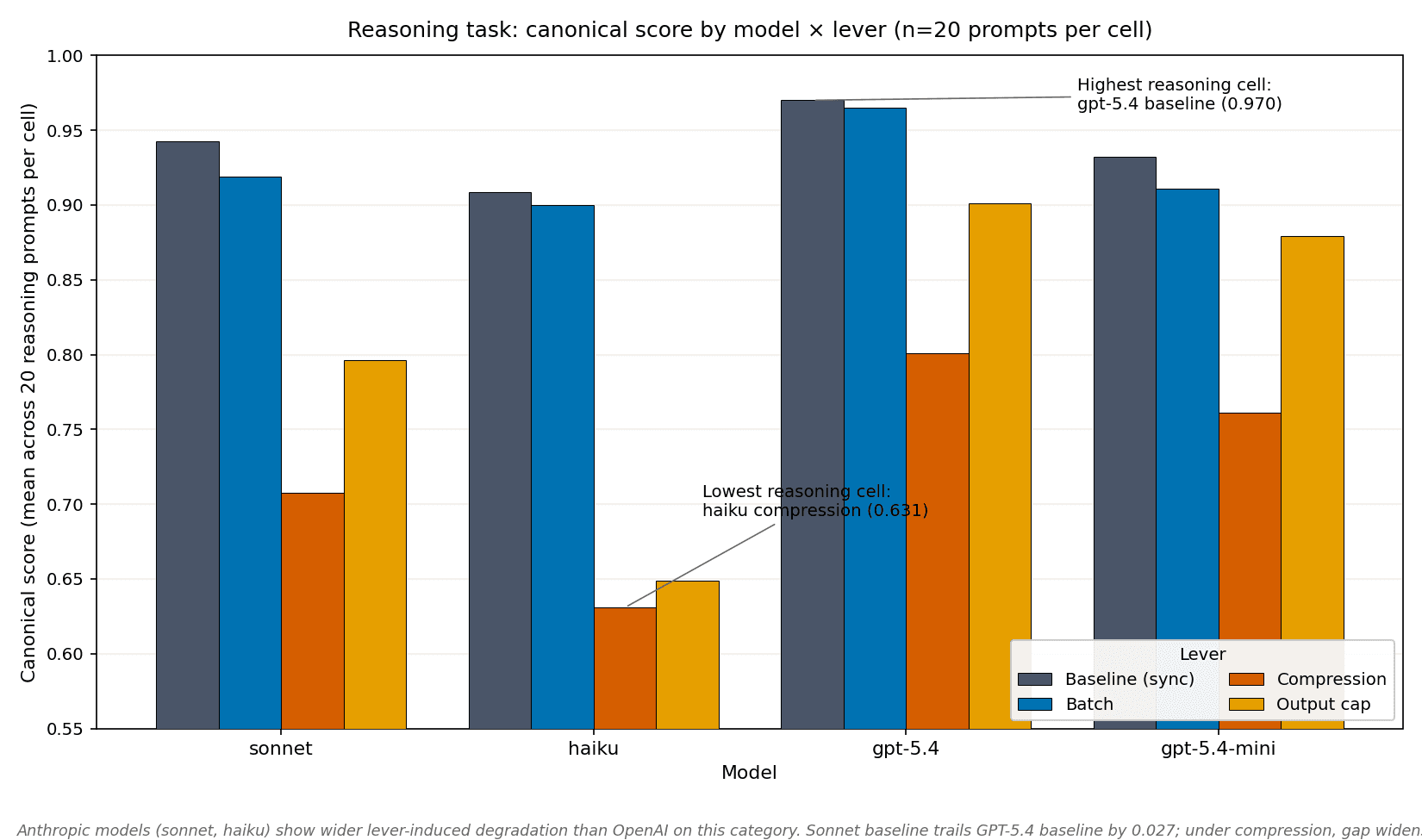
The same pattern shows on cost-tier models. Haiku reasoning canon falls from 0.909 (baseline) to 0.631 (compression) — a 28-point drop — versus gpt-5.4-mini's 17-point drop (0.932 → 0.761).
The practical implication is asymmetric: if you are running Anthropic models in production, avoid compression specifically on reasoning-heavy workloads. If you are running OpenAI, the same levers cost less.
Finding 6 — The cost-quality sweet spot depends on the task
For three of four task categories you can shop aggressively for cheap quality: customer_support has 9 cells within 90% of the category's best canonical score, spanning a 10.0× cost range; rag_qa has 9 cells at 8.9× spread; reasoning has 10 cells at 13.9× spread.
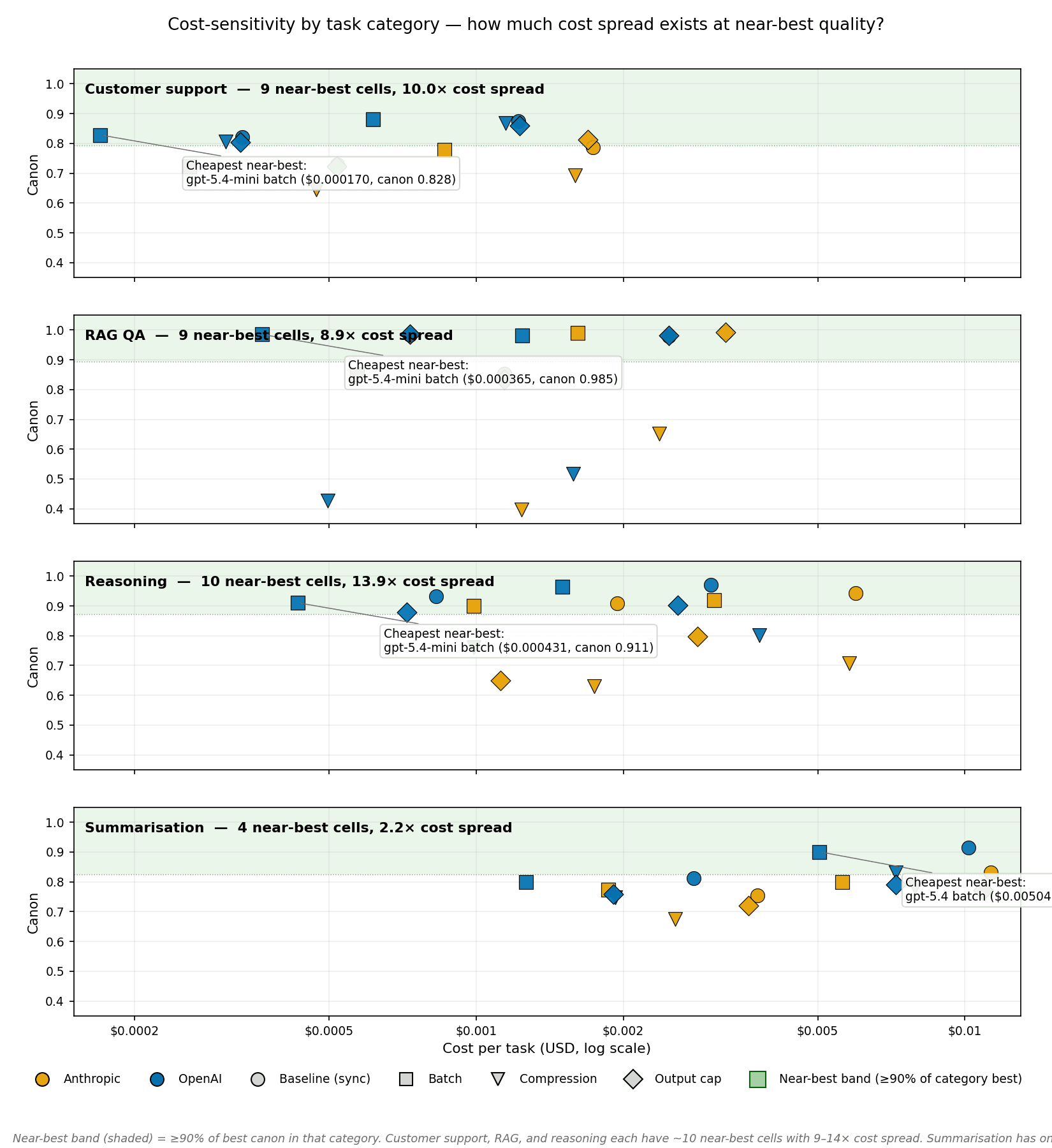
Summarisation is the exception. Only 4 cells reach 90% of the category's best canon, all within a narrow 2.2× cost range. Summarisation's cheapest near-best cell is gpt-5.4 batch at $0.005045 per task — 30× more expensive than the cheapest near-best cell in any other category.
The lesson is task-shaped routing. A production traffic mix that is 80% short-answer + 20% summarisation should route the short-answer share to gpt-5.4-mini batch (~$0.0004/task) and the summarisation share to gpt-5.4 batch (~$0.005/task) — a blended cost that is ~85% lower than routing everything to the frontier-quality cell.
The cost-quality sweet spot
Two scalar findings drop out of the analysis cleanly enough to write down as the v1 actionable recommendation:
Cheapest 94% of frontier quality: gpt-5.4-mini + batch. Canonical score 0.881 at $0.000557 per task. 94.2% of frontier quality at 13.2% of frontier cost.
Frontier quality cost: gpt-5.4 + baseline. Canonical score 0.935 at $0.004220 per task. Use when the 5.4-point canonical margin genuinely matters.
The cost premium between the two cells is 7.6× — for 5.4 canonical points. You can buy 94% of frontier quality for 13% of frontier cost by routing routine traffic to gpt-5.4-mini batch, and pay the 7.6× premium only on the share of traffic where the last 5.4 canonical points justify the cost. For a typical production mix this is a 70–85% cost reduction.
Limitations
This is a v1 benchmark with deliberate scope limits. Five constraints worth naming before you act on the findings:
- Single-shot scoring, no statistical replication. Each (prompt, model, lever) cell was scored once, not n=5 with confidence intervals. The findings are robust because effect sizes are large (−0.45 on RAG cannot be noise) and consistent across cells — but smaller deltas should be read as “indistinguishable” rather than directional.
- Same-family judge bias. Both judges are from the same model families as the test models. Residual same-family bias is possible but small; the headline findings reproduce on both judges individually.
- 102 prompts is a small benchmark. The benchmark's strength is methodological rigour per prompt; its weakness is sample size. Findings are strongest where they reproduce across categories.
- May 2026 snapshot. Model prices and capabilities move. Findings about lever effects should generalise; findings about specific Pareto positions will not. Recommended re-measurement cadence: quarterly.
- v2 plans, scoped. v2 plans include family-disjoint judges (Grok 4, fine-tuned evaluators), expanded model coverage, additional levers (prompt caching, structured outputs), and statistical replication (n=5 with bootstrap CIs).
Conclusion + early-adopter offer
We measured 1,280 scored responses across four production frontier models, four operational levers, and four Tier-2 task categories. The findings are: batch is a near-free 50% cost cut on every model and every task; compression destroys RAG specifically and is dominated everywhere else; output_cap is a reasoning-specific tax; OpenAI Pareto-dominates the aggregate frontier but Sonnet wins RAG; Anthropic models degrade more under optimisation pressure on reasoning; and the cost-quality sweet spot depends entirely on the task shape.
The actionable v1 recommendation for production routing is: gpt-5.4-mini + batch for everything that tolerates batch latency, with task-specific overrides — gpt-5.4 baseline or batch for summarisation, sonnet baseline or batch for RAG-heavy workloads, and explicit avoidance of compression on RAG and output_cap on reasoning.
If you are running LLM workloads in production and want to apply these findings to your actual workload — your prompts, your model mix, your traffic shape — we are taking on a small number of early adopters at no cost in exchange for working closely on the InferOps product, including informing v2 benchmark scope and methodology.
Source: data/results.db, n=1,280 Tier-2 rows. Methodology: prompt_design_decisions.md. Figures: analysis/out/charts/. Generated May 2026.